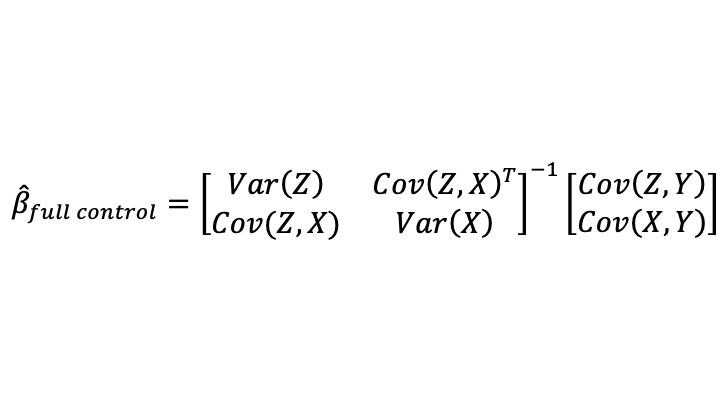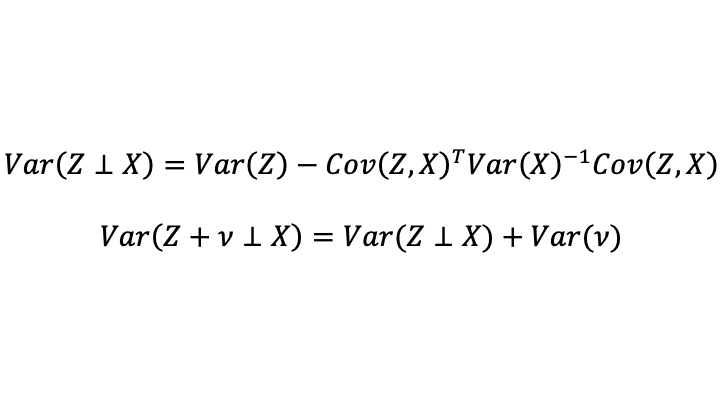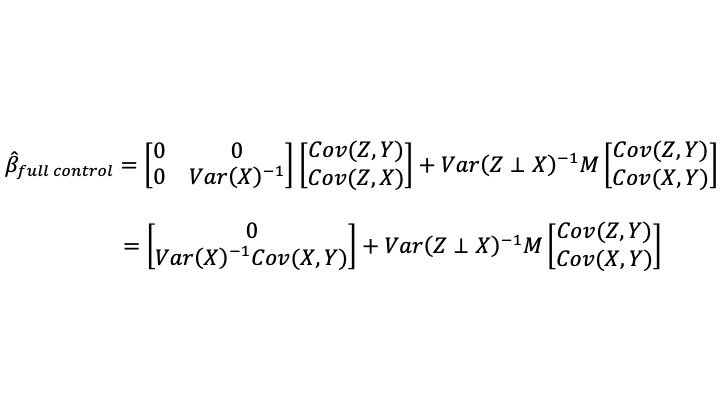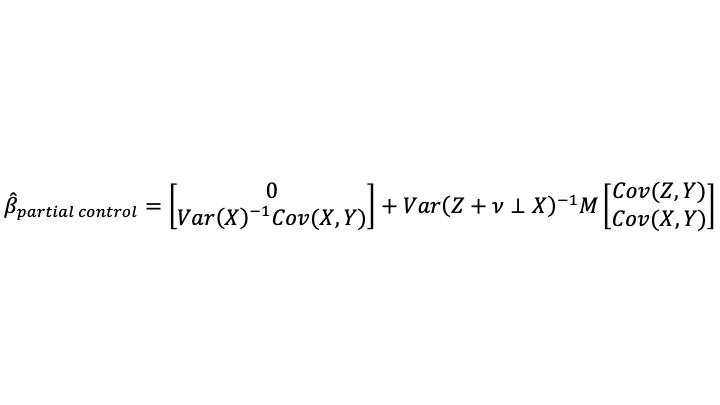Based on an article in “Obesity Reviews” by Santos, Esteves, Pereira, Yancy and Nunes entitled “Systematic review and meta-analysis of clinical trials of the effects of low carbohydrate diets on cardiovascular risk factors,” lowcarb diets look like (on average) they reduce
while raising HDL cholesterol (“good cholesterol”). But lowcarb diets don’t seem to reduce LDL cholesterol (“bad cholesterol”). This matches my own experience. In my last checkup my doctor said all of my blood work looked really good, but that one of my cholesterol numbers was mildly high.
Nutritionists often talk about the three “macronutrients”: carbohydrates, protein and fat. For nutritional health, many of the most important differences are within each category. Sugar and easily-digestible starches like those in potatoes, rice and bread are very different in their health effects than resistant starches and the the carbs in leafy vegetables. Animal protein seems to be a cancer promoter in a way that plant proteins are not. (And non-A2 cow’s milk contains a protein that is problematic in other ways.) Transfats seem to be quite bad, but as I will discuss today, there isn’t clear evidence that other dietary fats are unhealthy.
Between the three macronutrients, I think dietary fat doesn’t deserve its especially bad reputation—and protein doesn’t deserve its especially good reputation. Sugar deserves an even worse reputation than it has, but there are other carbs that are OK. Cutting back on bad carbs usually goes along with increasing either good carbs, protein or dietary fat. Many products advertise how much protein they have; but that is not necessarily a good thing.
Besides transfats, which probably deserve their bad reputation, saturated fats have the worst reputation among dietary fats. So let me focus on the evidence about saturated fat. One simple point to make is that saturated fats in many meat and dairy products tend to come along with animal protein. As a result, saturated fat has long been in danger of being blamed for crimes by animal protein. Butter doesn’t have that much protein in it, but tends to be eaten on top of the worst types of carbs, and so is in danger of being blamed for crimes by very bad carbs.
Part of the conviction that saturated fat is unhealthy comes from the effect of eating saturated fat on blood cholesterol levels. So any discussion of whether saturated fat is bad has to wrestle with the question of how much we can infer from effects on blood cholesterol. One of the biggest scientific issues there is that the number of different subtypes of cholesterol-transport objects in the bloodstream is considerably larger than the number of quantities that are typically measured. It isn’t just HDL cholesterol, tryglicerides and LDL cholestoral numbers that matter. The paper shown at the top of this post, “Systematic review and meta-analysis of clinical trials of the effects of low carbohydrate diets on cardiovascular risk factors,” explains:
Researchers now widely recognise the existence of a range of LDL particles with different physicochemical characteristics, including size and density, and that these particles and their pathological properties are not accurately measured by the standard LDL cholesterol assay. Hence assessment of other atherogenic lipoprotein particles (either LDL alone, or non-HDL cholesterol including LDL, intermediate density lipoproteins, and very low density lipoproteins, and the ratio of serum apolipoprotein B to apolipoprotein A1) have been advocated as alternatives to LDL cholesterol in the assessment and management of cardiovascular disease risk. Moreover, blood levels of smaller, cholesterol depleted LDL particles appear more strongly associated with cardiovascular disease risk than larger cholesterol enriched LDL particles, while increases in saturated fat intake (with reduced consumption of carbohydrates) can raise plasma levels of larger LDL particles to a greater extent than smaller LDL particles. In that case, the effect of saturated fat consumption on serum LDL cholesterol may not accurately reflect its effect on cardiovascular disease risk.
In brief, the abundance of cholesterol-transport object subtypes whose abundance isn’t typically measured separately could matter a lot for health. Some drugs that reduce LDL help reduce mortality; others don’t. The ones that reduce mortality could be reducing LDL by reducing some of the worst subtypes of cholesterol-transport objects, while the ones that don’t work could be reducing LDL by reducing some relatively innocent subtypes of cholesterol-transport objects. As Santos, Esteves, Pereira, Yancy and Nunes write in the article shown at the top of this post:
As the diet-heart hypothesis evolved in the 1960s and 1970s, the focus shifted from the effect of dietary fat on total cholesterol to LDL cholesterol. However, changes in LDL cholesterol are not an actual measure of heart disease itself. Any dietary intervention might influence other, possibly unmeasured, causal factors that could affect the expected effect of the change in LDL cholesterol. This possibility is clearly shown by the failure of several categories of drugs to reduce cardiovascular events despite significant reductions in plasma LDL cholesterol levels.
Another way to put the issue is that cross-sectional variation in LDL (“bad”) cholesterol levels for which higher LDL levels look bad for health may involve a very different profile of changes in cholesterol-transport object subtypes than eating more saturated fats from coconut milk, cream or butter would cause (in the absence of the bad carbs such as bread or potatoes that often go along with butter). Likewise, variation in LDL (“bad”) cholesterol levels associated with statin treatment in which statin drugs look good for reducing mortality may may involve a very different profile of changes in cholesterol-transport object subtypes than eating more saturated fats from coconut milk, cream or butter itself would cause.
The article “Systematic review and meta-analysis of clinical trials of the effects of low carbohydrate diets on cardiovascular risk factors” gives an excellent explanation of the difficulty in getting decisive evidence about the effects of eating saturated fat on disease. The relevant passage deserves to be quoted at length:
These controversies arise largely because existing research methods cannot resolve them. In the current scientific model, hypotheses are treated with scepticism until they survive rigorous and repeated tests. In medicine, randomised controlled trials are considered the gold standard in the hierarchy of evidence because randomisation minimises the number of confounding variables. Ideally, each dietary hypothesis would be evaluated by replicated randomised trials, as would be done for the introduction of any new drug. However, this is often not feasible for evaluating the role of diet and other behaviours in the prevention of non-communicable diseases.
One of the hypotheses that requires rigorous testing is that changes in dietary fat consumption will reduce the risk of non-communicable diseases that take years or decades to manifest. Clinical trials that adequately test these hypotheses require thousands to tens of thousands of participants randomised to different dietary interventions and then followed for years or decades until significant differences in clinical endpoints are observed. As the experience of the Women’s Health Initiative suggests, maintaining sufficient adherence to assigned dietary changes over long periods (seven years in the Women’s Health Initiative) may be an insurmountable problem. For this reason, among others, when trials fail to confirm the hypotheses they were testing, it is impossible to determine whether the failure is in the hypothesis itself, or in the ability or willingness of participants to comply with the assigned dietary interventions. This uncertainty is also evident in diet trials that last as little as six months or a year.
In the absence of long term randomised controlled trials, the best available evidence on which to establish public health guidelines on diet often comes from the combination of relatively short term randomised trials with intermediate risk factors (such as blood lipids, blood pressure, or body weight) as outcomes and large observational cohort studies using reported intake or biomarkers of intake to establish associations between diet and disease. Although a controversial practice, many, if not most, public health interventions and dietary guidelines have relied on a synthesis of such evidence. Many factors need to be considered when using combined sources of evidence that individually are inadequate to formulate public health guidelines, including their consistency and the likelihood of confounding, the assessment of which is not shared universally. The level of evidence required for public health guidelines may differ depending on the nature of the guideline itself.
That is the state of the solid evidence. In terms of common notions that many people, including doctors, have in their heads, one should be aware of the hysteresis (lock-in from past events) in attitudes toward fat. Techniques of measuring overall cholesterol concentrations in the blood became possible in the early 20th century. Tentative conclusions reached then based on what would now clearly be recognized as a too-low-dimensional measurement of cholesterol have continued to effect attitudes even now, the better part of a century later. And the decision of the McGovern committee on dietary guidelines to advise against dietary fat rather than advise against sugar—which was a nonobvious duel among competing experts at the time—became dogma for a long time. Thankfully, the idea that dietary fat is worse than sugar is weakening as a dogma, so there is a chance now for scientific evidence to play a decisive role. If only solid evidence were easier to come by!
No one knows the truth of the matter about dietary fat. And many doctors know less then you do now if you have made it to the end of this post. Where have I placed my bets? Eliminating sugar and other bad carbs from my diet would make my diet too bland for comfort if I didn’t allow a lot of fats. I eat a lot of avocados and a lot of olive oil, which most experts think have quite good fats. (See “In Praise of Avocados.”) But I also eat quite a bit of coconut milk, cream and butter (without the bread or potatoes!) I don’t know if that is OK, but I feel quite comfortable doing so.
In addition to all of the evidentiary problems mentioned above, very few clinical trials look at the effects of what kinds of fats people eat when they are fasting regularly (that is, going without food for extended periods of time). It may be just my optimism, but if saturated fats do have some bad effects, I have some hope that fasting gives my body time to repair any damage that may result.
I dream of a day when there will be funds to do types of dietary research that have been underdone. I think research funding has been skewed toward cure of diseases people already have over research that can help prevention. Hopefully, that skewing will someday be rectified.
For annotated links to other posts on diet and health, see: